Uni3DR2:
Unified Scene Representation and Reconstruction for 3D Large
Language Models
Abstract
Enabling Large Language Models (LLMs) to interact with 3D environments is challenging. Existing approaches extract point clouds either from ground truth (GT) geometry or 3D scenes reconstructed by auxiliary models. Text-image aligned 2D features from CLIP are then lifted to point clouds, which serve as inputs for LLMs. However, this solution lacks the establishment of 3D point-to-point connections, leading to a deficiency of spatial structure information. Concurrently, the absence of integration and unification between the geometric and semantic representations of the scene culminates in a diminished level of 3D scene understanding. In this paper, we demonstrate the importance of having a unified scene representation and reconstruction framework, which is essential for LLMs in 3D scenes. Specifically, we introduce Uni3DR2 extracts 3D geometric and semantic aware representation features via the frozen pre-trained 2D foundation models (e.g., CLIP and SAM) and a multi-scale aggregate 3D decoder. Our learned 3D representations not only contribute to the reconstruction process but also provide valuable knowledge for LLMs. Experimental results validate that our Uni3DR2 yields convincing gains over the baseline on the 3D reconstruction dataset ScanNet (increasing F-Score by +1.8\%). When applied to LLMs, our Uni3DR2-LLM exhibits superior performance over the baseline on the 3D vision-language understanding dataset ScanQA (increasing BLEU-1 by +4.0\% and +4.2\% on the val set and test set, respectively). Furthermore, it outperforms the state-of-the-art method that uses additional GT point clouds on both ScanQA and 3DMV-VQA.
🔥Highlight
- We propose Uni3DR2, a Unified Scene Representation and Reconstruction for 3D Large Language Models.
- Our Uni3DR2 yields convincing gains over the baseline on the 3D reconstruction dataset ScanNet (increasing F-Score by +1.8\%).
- Our Uni3DR2-LLM exhibits superior performance over the baseline on the 3D vision-language understanding dataset ScanQA (increasing BLEU-1 by +4.0\% and +4.2\% on the val set and test set, respectively). Furthermore, it outperforms the state-of-the-art method that uses additional GT point clouds on both ScanQA and 3DMV-VQA.
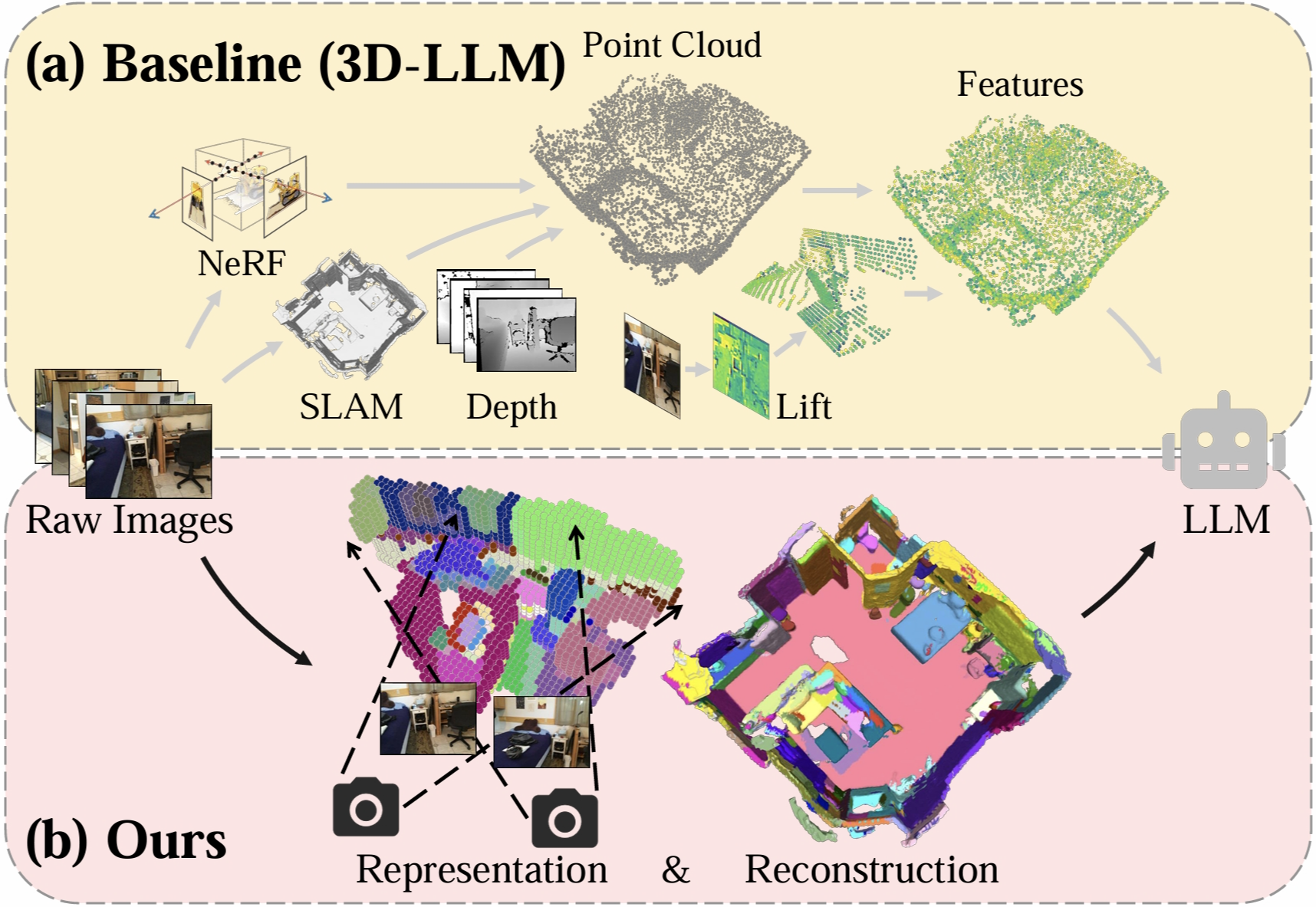
Comparison
Comparison between the representation for 3D LLMs. (a) The previous baseline is isolated and complex, which requires extra NeRF, SLAM models, or depth to extract the point cloud and then lifts features to the 3D representations.
(b) By contrast, our Uni3DR2 is unified and neat. We unified learn geometric and semantically rich volumetric representation with high-quality reconstruction as LLM inputs. Our learned representation and reconstruction significantly enhance the LLM's performance in 3D environments.
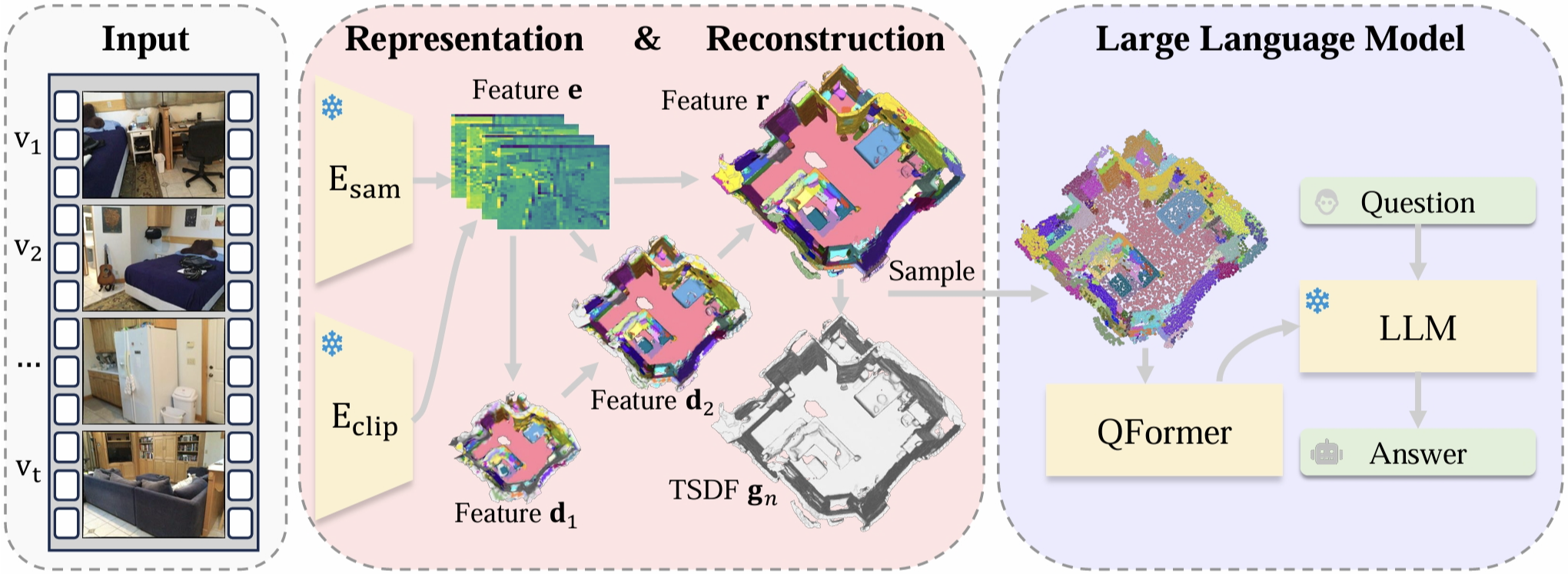
Uni3DR2-LLM Framework
Overview of our Uni3DR2-LLM framework. Given video inputs, Uni3DR2-LLM employs
(1) a frozen encoder integrating SAM and CLIP image encoders, followed by a decoder for 3D representations,
(2) a light-weight module focus on \textbf{3D reconstruction}, and
(3) an LLM integrated with QFormer for 3D vision-language understanding.
(❄: frozen.).
Demo of Uni3DR2-LLM
Video Demo of Reconstruction and Representation for 3D LLM.
Reconstruction of Uni3DR2
3D reconstruction visualization results on ScanNet.
Compared to the baseline method (second column), our method (third column) predicts the reconstruction results with more semantic details.

Question and Answer of Uni3DR2-LLM
3D vision-language understanding visualization results.
Our Uni3DR2-LLM predicts accurate reconstructions and answers the user input questions.

Acknowledgment
This work is supported by Guangdong Basic and Applied Basic Research Foundation (Grant No.2024A1515012043), the National Key R & D Program of China (2022ZD0160201), and Shanghai Artificial lntelligence Laboratory.
BibTeX
@misc{chu2024unified,
title={Unified Scene Representation and Reconstruction for 3D Large Language Models},
author={Tao Chu and Pan Zhang and Xiaoyi Dong and Yuhang Zang and Qiong Liu and Jiaqi Wang},
year={2024},
eprint={2404.13044},
archivePrefix={arXiv},
primaryClass={cs.CV}
}